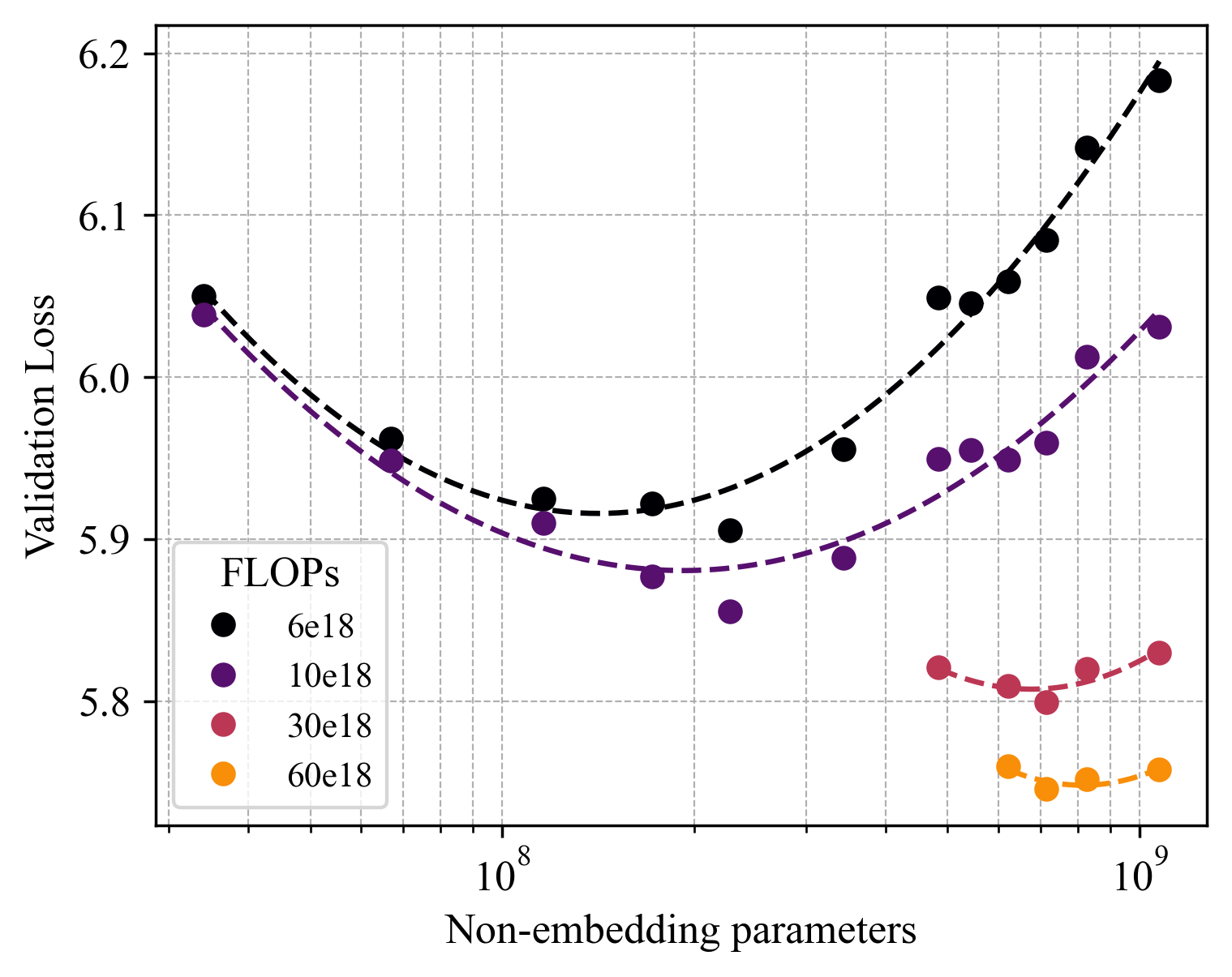
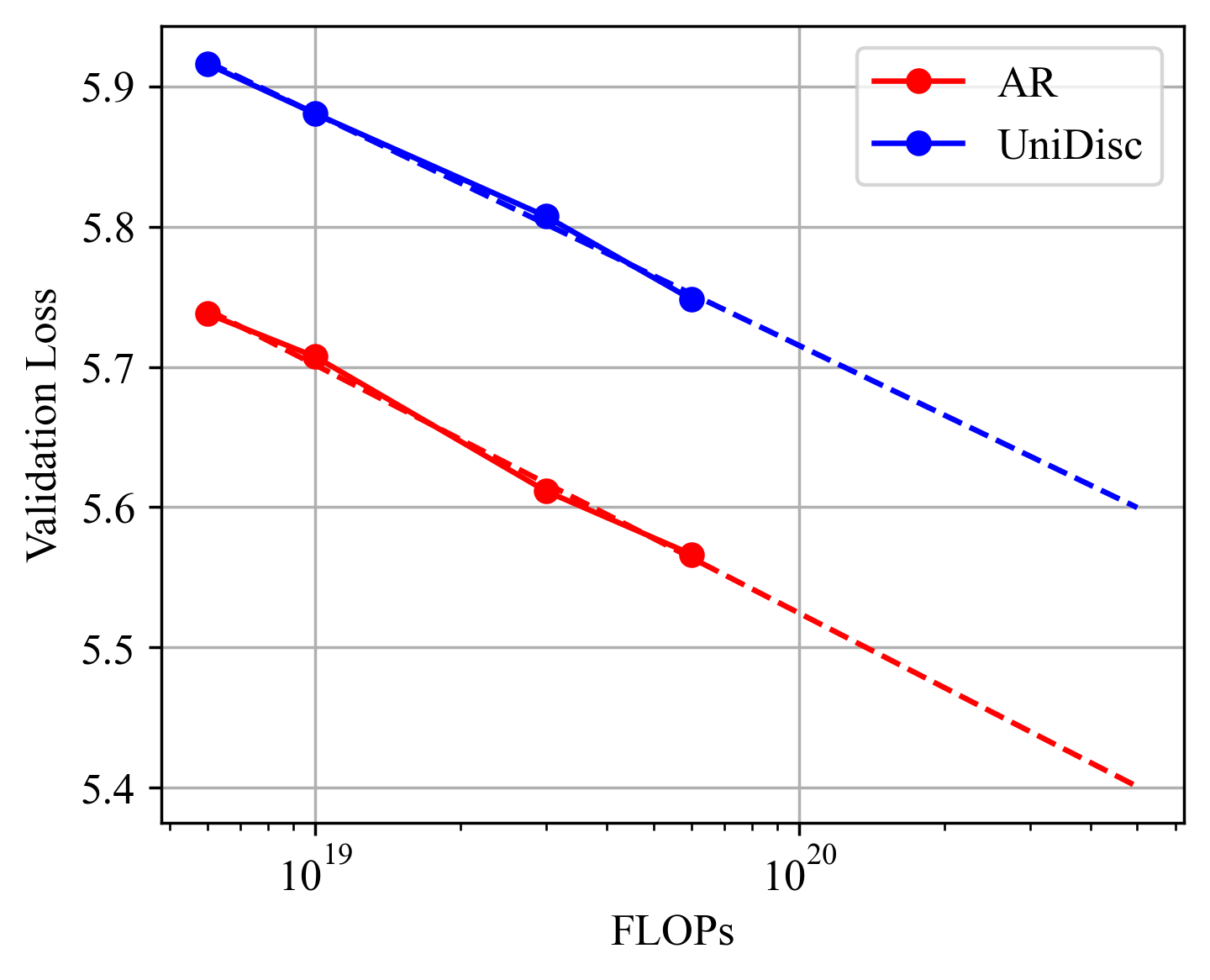
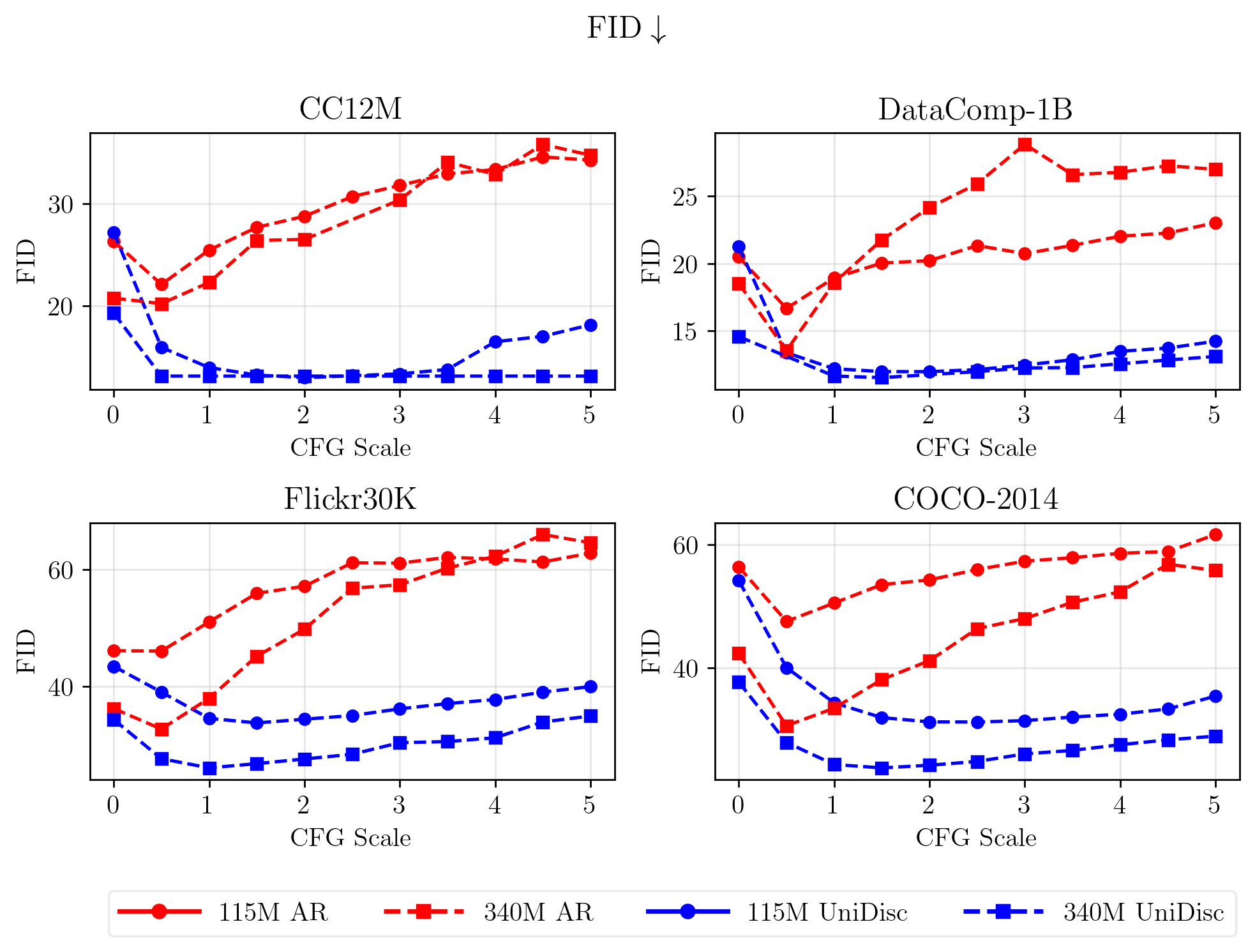
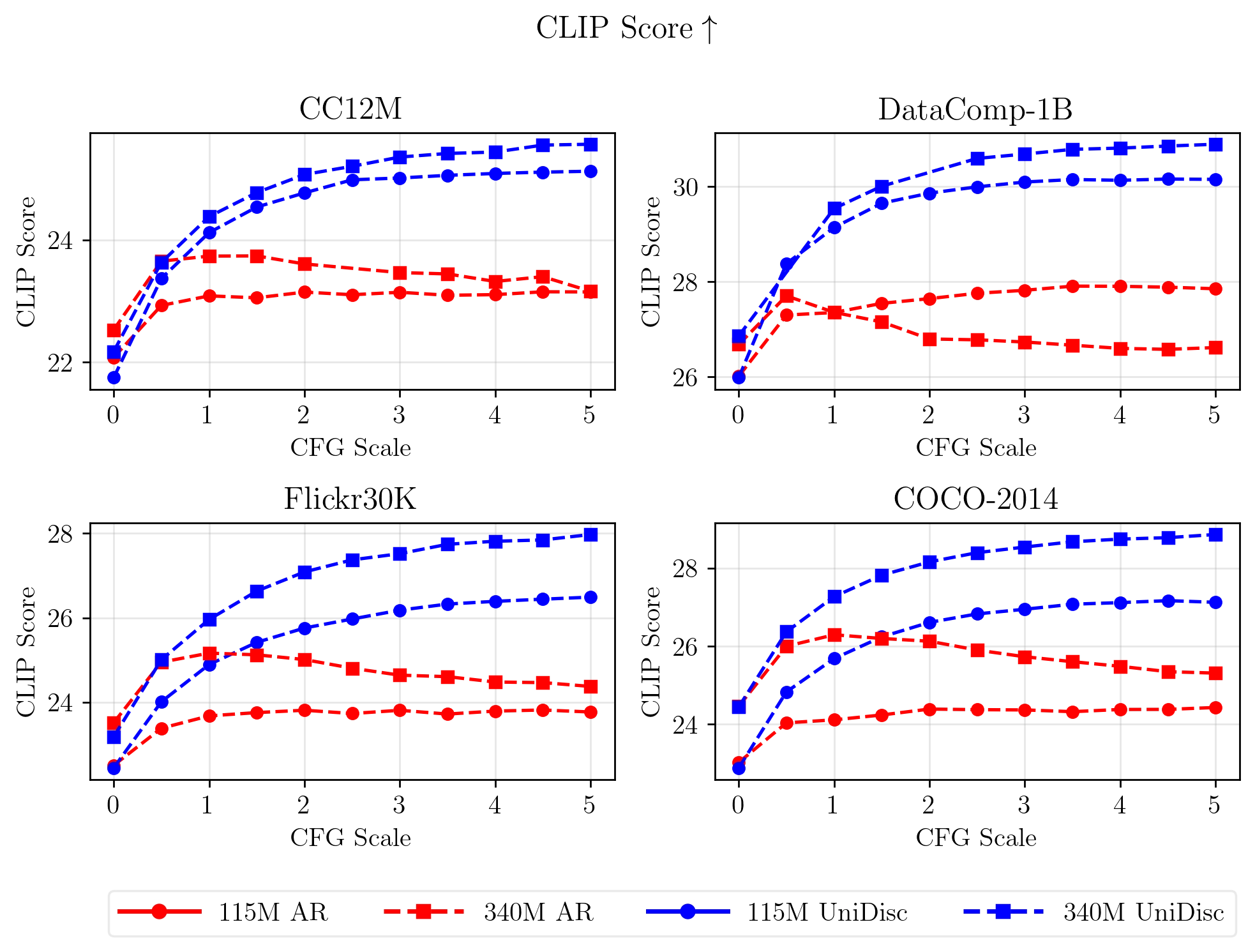
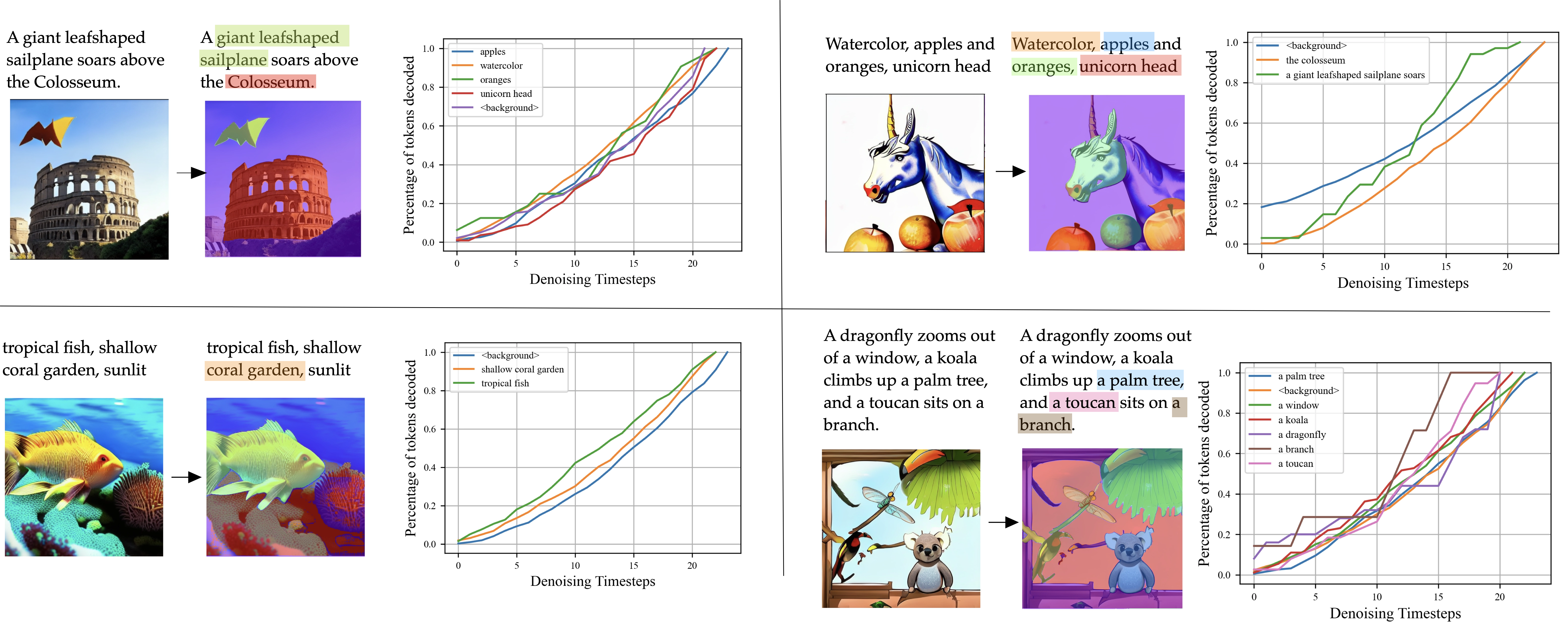
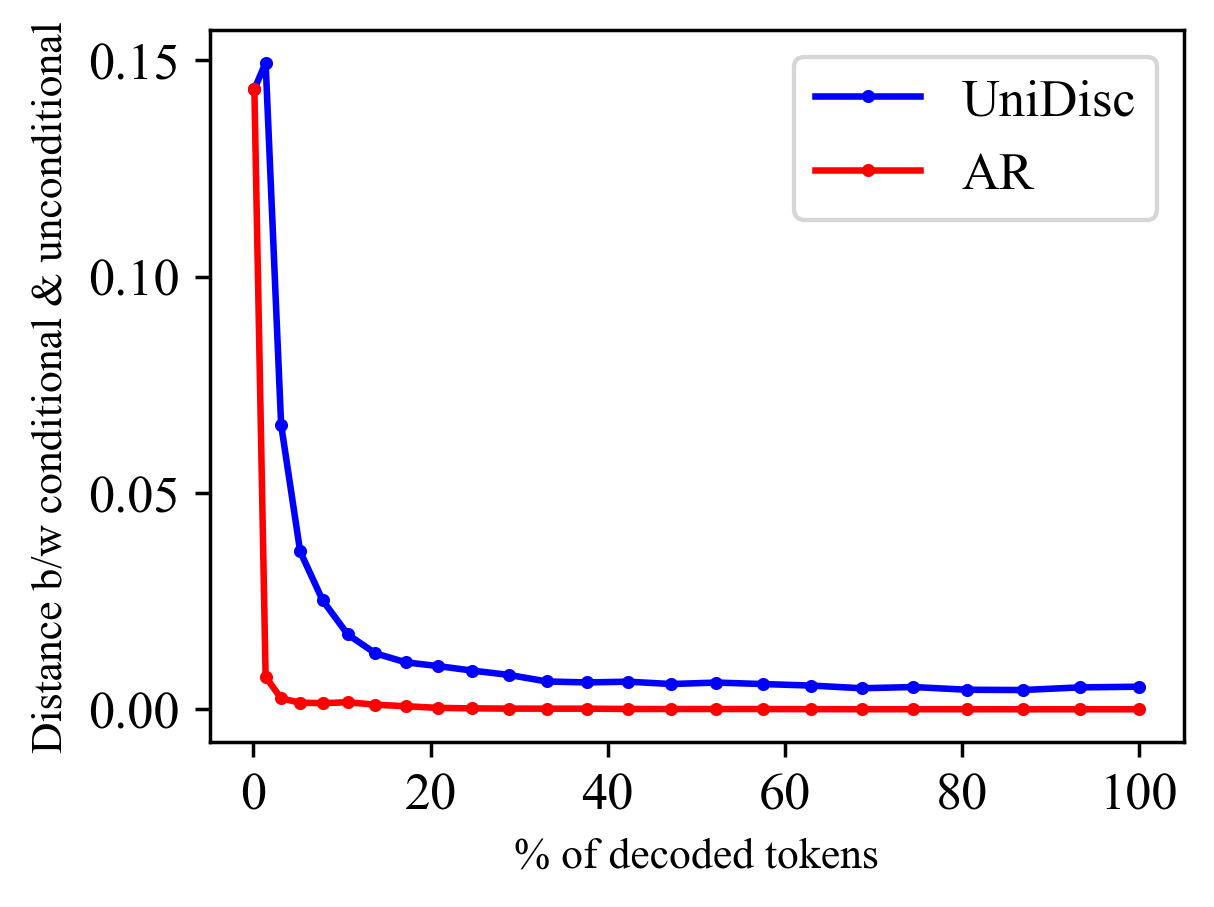
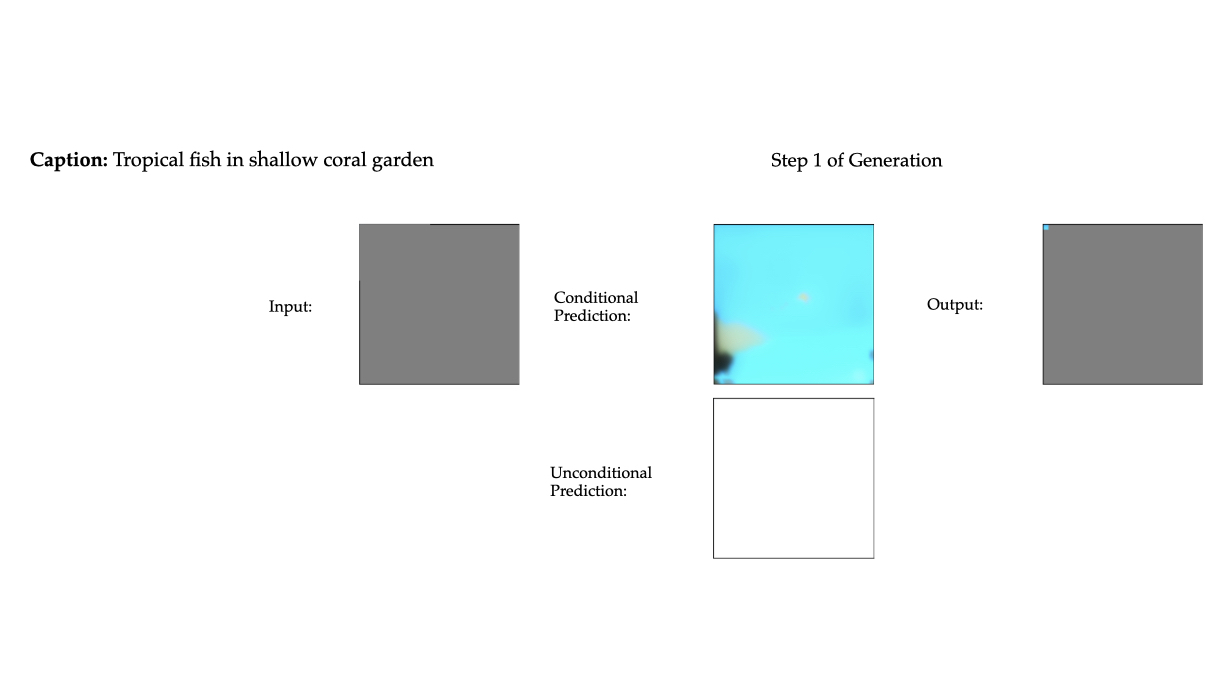
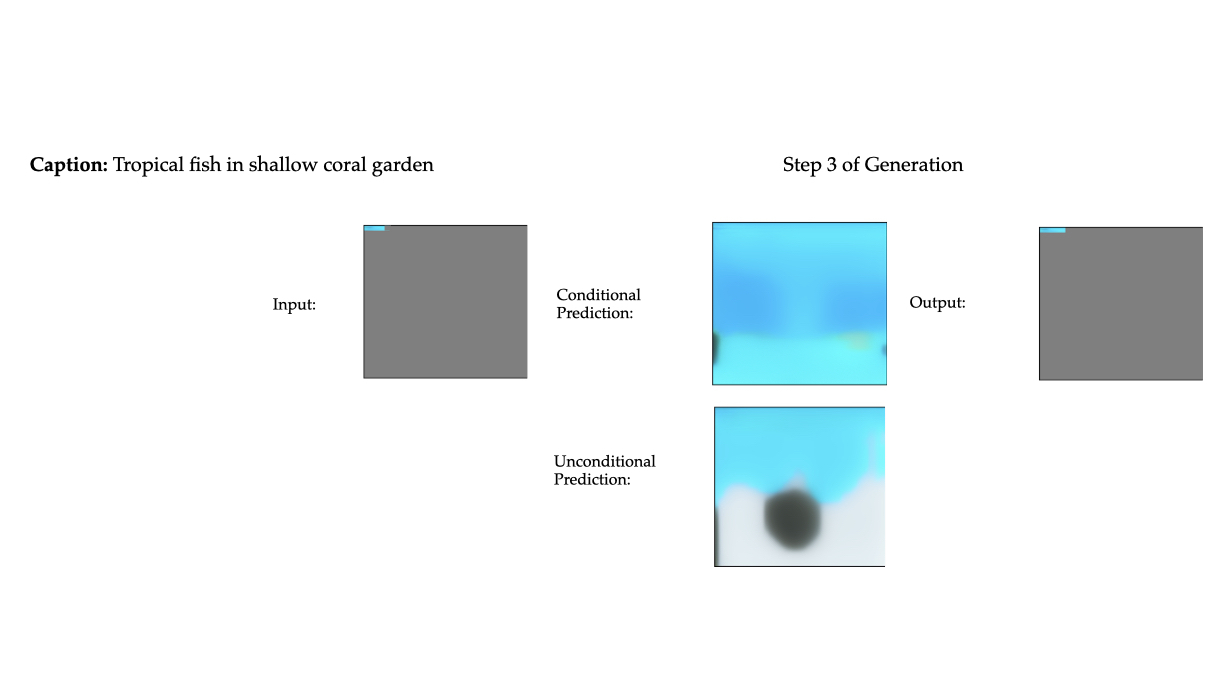
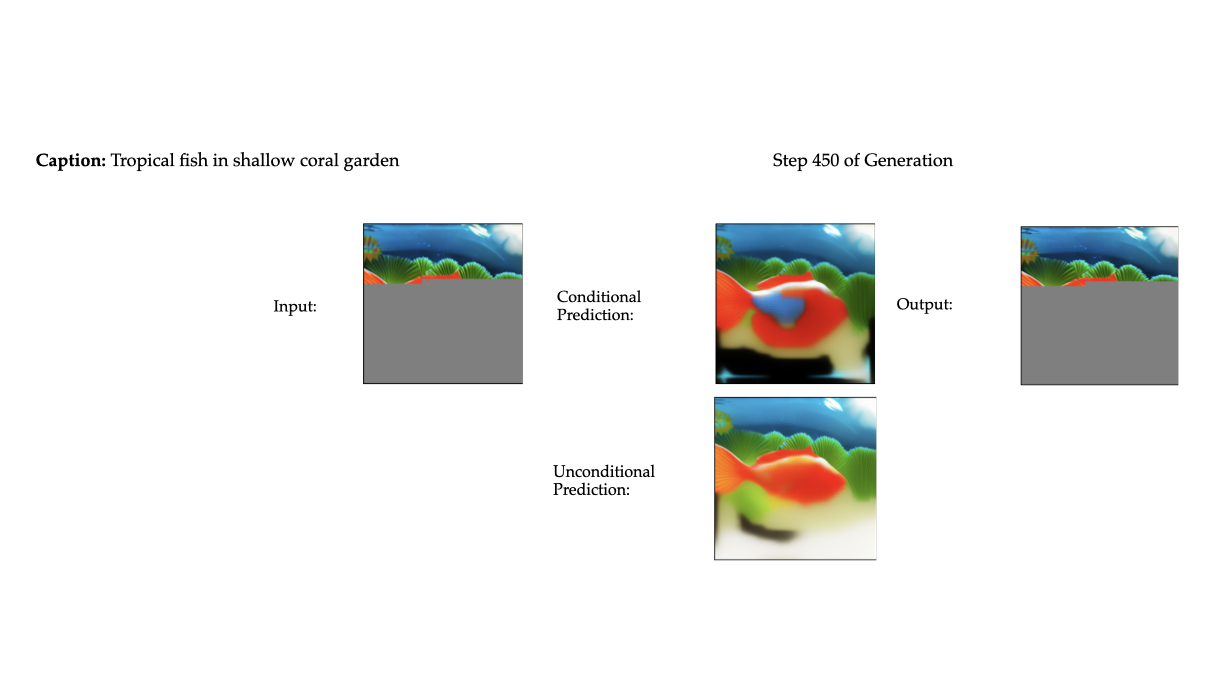
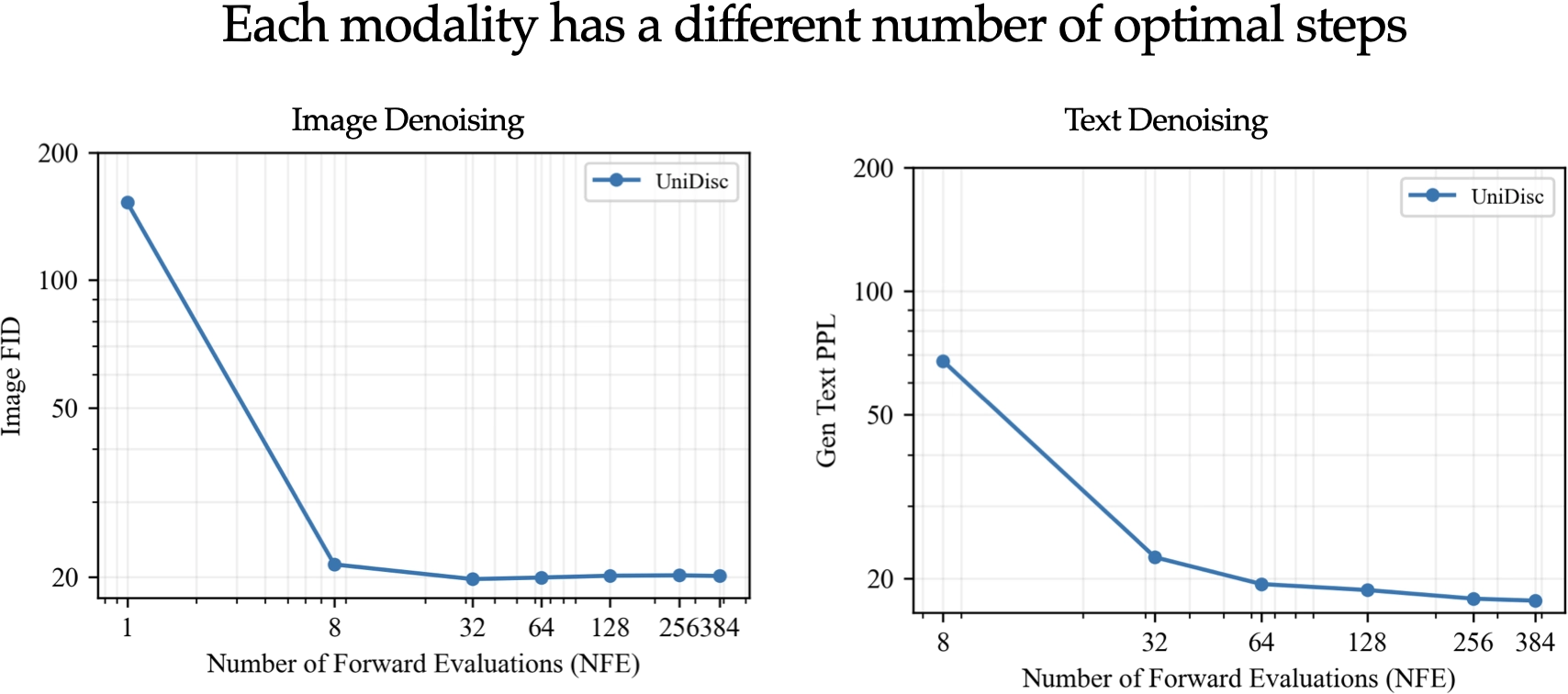
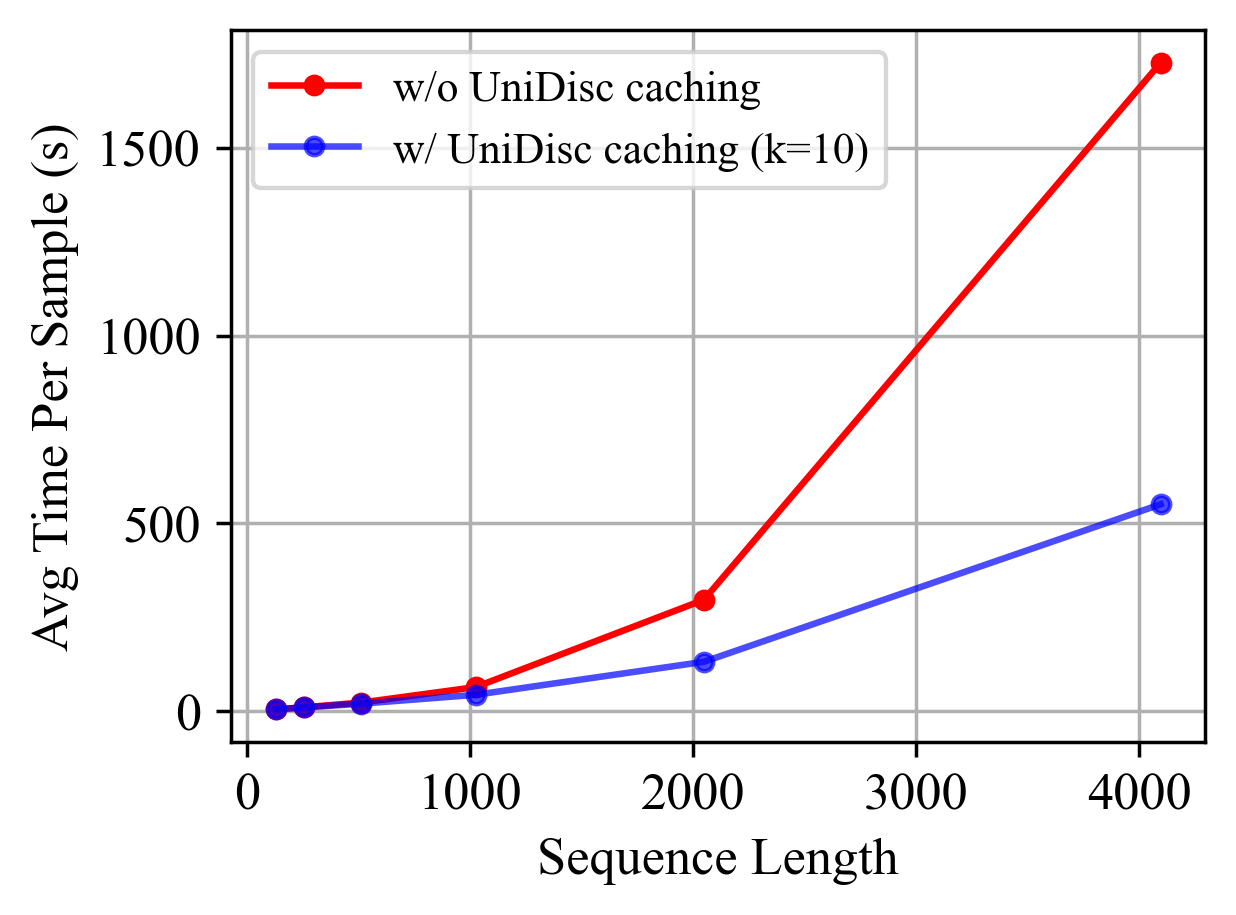
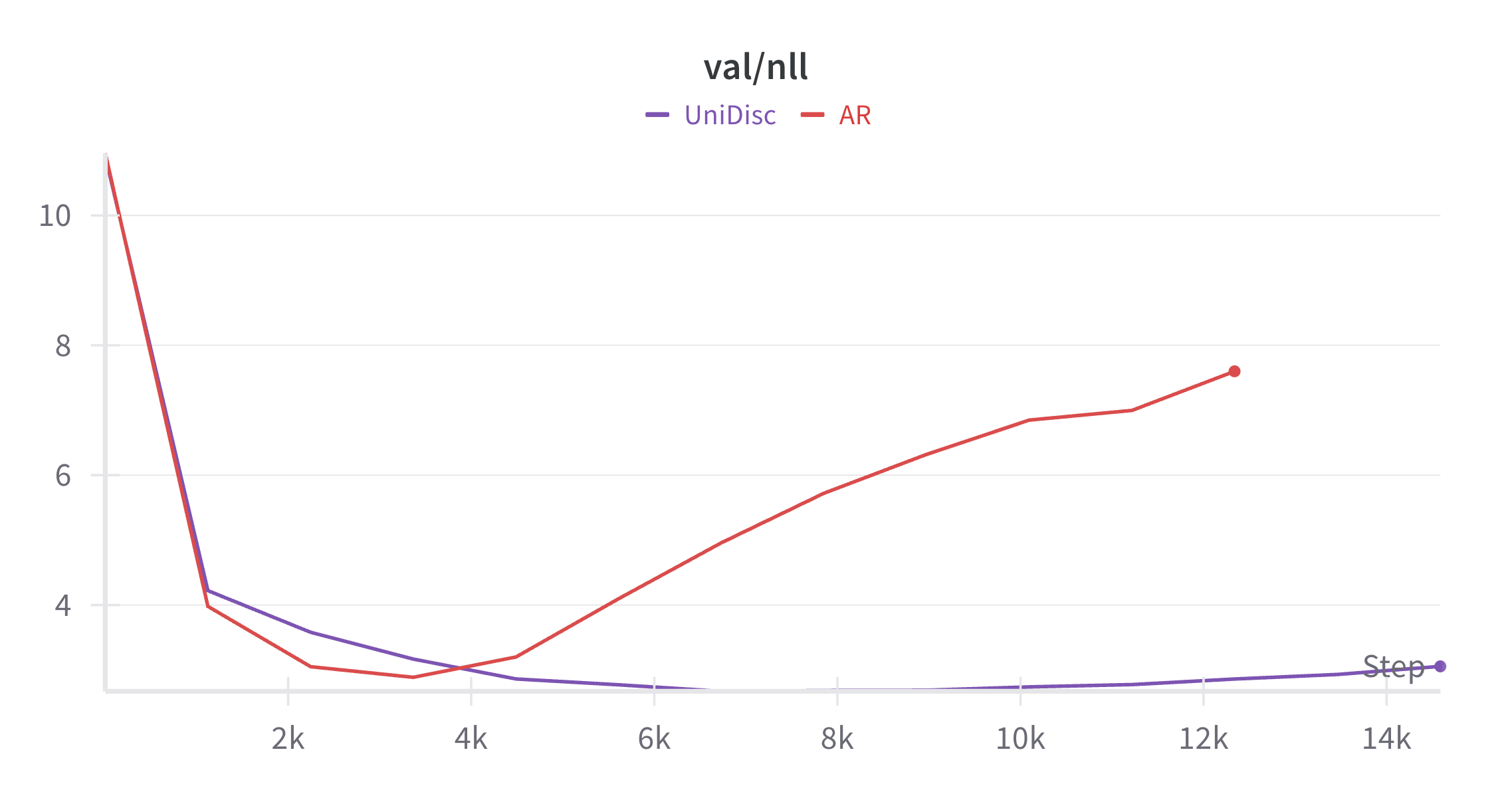
Multimodal generative models that can understand and generate across multiple modalities are dominated by autoregressive (AR) approaches, which process tokens sequentially from left to right, or top to bottom. These models jointly handle images, text, video, and audio for various tasks such as image captioning, question answering, and image generation. While AR models have been highly successful in the text domain, they have been found suboptimal for processing images, videos, and audio due to the high correlation between adjacent tokens which waste inference-time compute by separately predicting each one. In this work, we explore discrete diffusion models as a unified generative formulation in the joint text and image domain, building upon their recent success in the text domain alone. Discrete diffusion models offer several advantages over AR models, including improved control over quality versus diversity of generated samples, the ability to perform joint multimodal inpainting (across both text and image domains), and greater controllability in generation through guidance. Leveraging these benefits, we present the first Unified Multimodal Discrete Diffusion (UniDisc) model, which is capable of jointly processing text and images for a variety of downstream tasks. We compare UniDisc to multimodal AR models of similar capacity, demonstrating that UniDisc outperforms them in terms of both performance and inference-time compute, enhanced controllability, editability, inpainting, and flexible trade-off of inference time versus generation quality.